

.jpg)
The Akaike Edge
Executive Summary
At Akaike, a GenAI company, we support clients who serve large and linguistically diverse audiences where the speed and scale of content creation are critical strategic priorities. This report presents a focused engineering effort to address the audio generation gap for Indic languages — particularly Hindi and Hinglish — by combining open-source model adaptation, emotion-aware fine-tuning, and rigorous production-grade evaluation. The result is a meaningful improvement in expressive speech quality, enabling reliable and character-consistent audio generation at scale.
Problem Statement
Generative AI is rapidly redefining how content is created and distributed at scale. For anyone exploring the future of media — especially across diverse languages, formats, and audience segments — the ability to generate high-quality audio programmatically is no longer just a forward-looking capability; it is becoming a practical necessity.
At the same time, progress across modalities has been uneven. Visual generation technologies have evolved quickly, but audio generation has lagged behind, particularly for Indic languages. This imbalance is creating a growing disconnect between what video generation pipelines can produce and what audio systems can consistently support. As a result, audio remains one of the key constraints in building truly end-to-end AI-powered content production workflows.
The core problem is threefold:
- Indic language speech systems lag behind English counterparts in expressiveness and reliability.
- Existing commercial and open-source tools fail to maintain character voice consistency in terms of prosody or emotional fidelity.
- No off-the-shelf solution adequately addresses the prosodic and phonetic complexity of Hindi and Hinglish content.
Technical Challenges
Speech generation systems that appear stable in controlled demonstrations frequently degrade under real-world workloads. For Indic languages, four structural limitations drive this failure:
- Scarcity of Expressive Training Data: Indic speech datasets are dominated by neutral narration. Emotionally diverse, character-driven data — the kind required for cinematic or conversational content — is largely absent. Models trained on these distributions are unable to produce emotionally aligned output in expressive settings.
- Instability Under Production Workloads: At scale, pipelines require long-form narration, repeated character appearances, and frequent regeneration. Under these conditions, speech systems exhibit emotional flattening, pronunciation drift, and audible inconsistency across inference calls — failure modes that accumulate quickly and are difficult to correct after generation.
- Insufficiency of Prompt-Based Control: Surface-level prompt conditioning can influence general tone but cannot enforce consistency or repeatability across generations. Without explicit modeling of emotion, phonetics, and stability constraints, prompt-level approaches fall short of production reliability requirements.
- Linguistic Complexity and Code-Switching: Hindi and Hinglish speech relies heavily on prosody, vowel duration, and rhythmic stress — all of which strongly influence perceived naturalness. Most systems lack language-aware mechanisms to resolve code-switching reliably, leading to inconsistent or unnatural outputs when Hindi and English tokens are closely interleaved.
Models Evaluated
These model architectures — representing the current state-of-the-art approaches in voice cloning — were evaluated to determine the most suitable foundation for scalable, production-grade deployment.
Non-Autoregressive / Parallel TTS (e.g., IndicF5)
These models predict acoustic features in a single forward pass. They offer low latency and stable outputs but handle expressiveness through auxiliary predictors rather than implicit sequence modeling. In practice, this produces consistent but perceptually flat speech with limited capacity to preserve character traits across repeated generations.
Latent / Diffusion-Inspired Models (e.g., VibeVoice)
These models operate in a compressed latent acoustic space, iteratively refining representations conditioned on text. While theoretically capable of capturing global acoustic structure, VibeVoice's lack of Indic language pretraining resulted in unstable behavior at inference — with significant variability in emotional alignment, pronunciation accuracy, and voice consistency across runs.
LLM-Backed Generative Speech Models (Chatterbox — Selected)
Chatterbox-class architectures frame speech synthesis as conditional token generation. A large causal transformer autoregressively predicts speech tokens, jointly conditioned on the target text and a reference audio clip. This design was selected for two reasons:
- Prosody and emotional expression are learned through sequence modeling of speech tokens, while timbre is handled in a later stage of the pipeline rather than being produced simultaneously by a single model.
- Additionally, conditioning the generation process on text, speaker embeddings, and reference speech tokens helps stabilize the output. This joint conditioning reduces voice drift and improves character voice consistency across different inference runs.
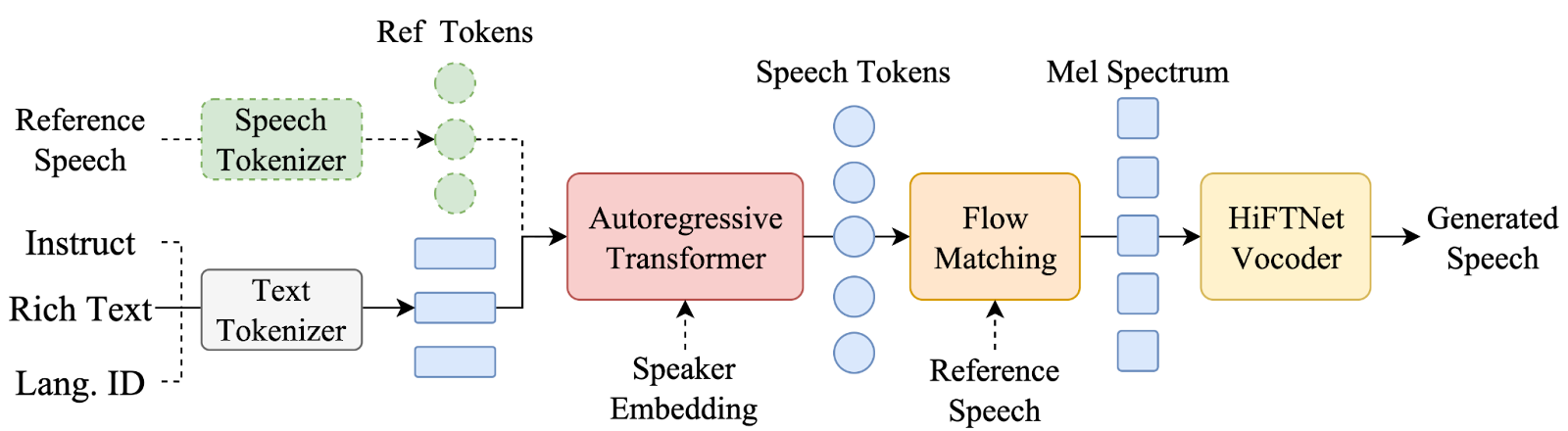
Solution
Our approach is modular: targeted fine-tuning of the generative core, supported by high-fidelity data engineering and language-aware preprocessing. The objective was to inject expressive and language-specific priors without compromising pronunciation stability or speaker identity.
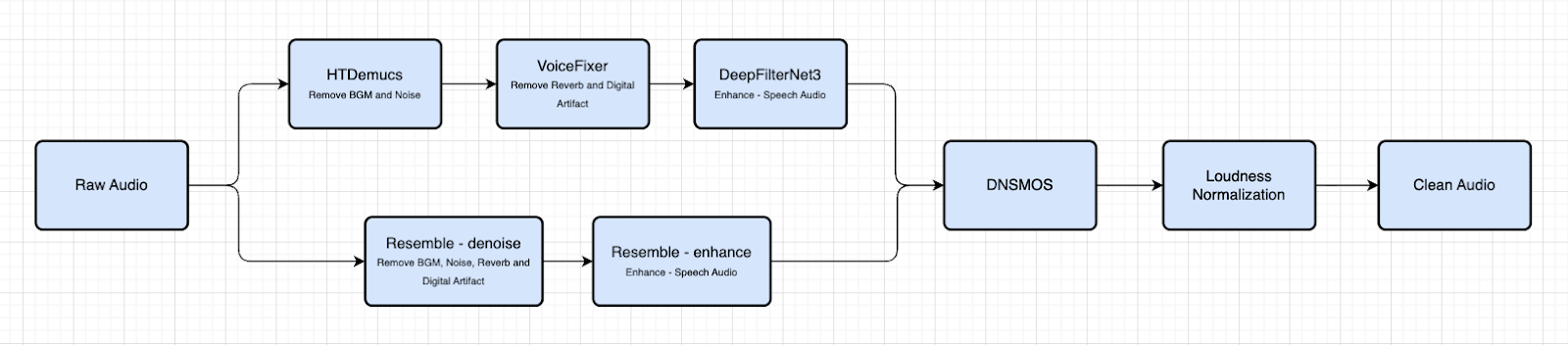
Data Pipeline
Given the scarcity of high-quality expressive Indic audio, a multi-stage pipeline was engineered to elevate low-quality source material:
- Noise reduction and speech isolation via HTDemucs
- Reverb and digital artifact removal via VoiceFixer
- Final speech refinement via DeepFilter
- An alternative single-stage approach using resemble-enhance
- Automated quality control using DNSMOS scoring — only high-quality files retained
- Loudness normalization for training consistency
Expressive speech generation requires emotionally diverse and accurately labeled training data. To address this at scale, an automated annotation pipeline was developed:
- Speaker diarization and segmentation to isolate character-specific audio
- Paired audio-transcript segments submitted to LLM annotators (Qwen and Gemini) for emotion classification
- Classification across a predefined emotion taxonomy, with post-processing and filtering to minimize annotation noise
Fine-Tuning Strategy
Fine-tuning was applied selectively to the Text-to-Token (T3) generative component, with the speech tokenizer, decoder, and vocoder kept frozen. The training objective was not to alter voice identity, but to shift the model's conditional speech token distribution from a generalized average toward character-specific expressive patterns.
Key training parameters:
- Dataset: approximately one hour of high-quality, expressive Hindi and Hinglish speech of any particular distinct speakers
- Language composition: cross-lingual (Hindi and English) to address code-switching phenomena
- Optimizer: AdamW with learning rate 1×10⁻⁵ and cosine scheduling (10% warm-up)
- Duration: 10 epochs with early stopping (patience = 3) to prevent overfitting
- Gradient clipping applied for training stability
Production Mitigations
Two recurring failure modes were identified during evaluation and systematically addressed:
Gibberish Artifacts in Short Utterances — Short sequences provide fewer autoregressive steps, increasing sensitivity to distribution shifts at generation boundaries. Root cause analysis led to targeted mitigations at the generation boundary level and in data curation. The issue was resolved in post-mitigation inference.
Pronunciation Errors in Hinglish Vocabulary — Code-switched inputs exposed instability in text-to-phoneme alignment for domain-specific terms. A pre-inference transcript normalization strategy using a lightweight lexicon mapping was implemented. This normalization improved pronunciation consistency without affecting overall fluency.
Performance Improvements & Business Value
Fine-tuning outcomes were evaluated against the base Chatterbox model across four production-critical metrics. Results are based on multiple inference runs to reflect production stability rather than best-case single-run performance.
Key Observations
- Emotional Alignment (+19%): The fine-tuned model produces speech that more faithfully reflects the intended emotional register of the script — a critical requirement for character-driven and narrative content.
- Speaker Similarity (+27%): Voice identity is preserved more consistently across repeated generations, enabling reliable character representation at production scale. The fine-tuned model also surpasses some close-source proprietary models on this metric.
- Pronunciation Accuracy (+23%): Correct pronunciation of domain-specific and code-switched vocabulary has improved substantially, reducing post-generation correction overhead.
- Human Perception (MOS +27%): The achieved MOS score places the fine-tuned model very close to leading commercial benchmarks, highlighting the strong performance of an open-source system that has been internally adapted and optimized.
* Note: the number are % improvements compared to pretrained models
Business Value
These technical improvements translate directly into operational and strategic value:
- Scalable audio generation also enables personalized, user-specific advertising by dynamically producing tailored voice content at scale, reducing reliance on manual voice recording and traditional studio production workflows.
- Faster time-to-publish: automated, reliable audio generation accelerates multi-language content pipelines.
- Consistent character identity: stable speaker similarity across runs enables reusable voice assets for recurring characters and narrators.
- Competitive capability parity: performance benchmarking against commercially available model demonstrates that production-grade quality is achievable with internally adapted open-source systems — at significantly lower marginal cost per generation.
- Foundation for scale: the methodology — data pipeline, emotion annotation, selective fine-tuning — is replicable across additional Indic languages and content formats.
Conclusion
By combining LLM-assisted data curation, a high-fidelity audio processing pipeline, and targeted fine-tuning of the Chatterbox generative core, we were able to materially advanced its capability to generate expressive, character-consistent Hindi and Hinglish speech. The results — including a 27% improvement in speaker similarity and a Mean Opinion Score approaching commercial benchmark levels — demonstrate that open-source adaptation, when executed with rigor, can meet the quality bar required for AI-driven content pipelines. This work establishes a repeatable methodology and a validated foundation for expanding generative audio capabilities across additional Indic languages and content verticals.

.png)
.png)

